NEXT
NEXT
How to Deploy an AI Model with PyTriton
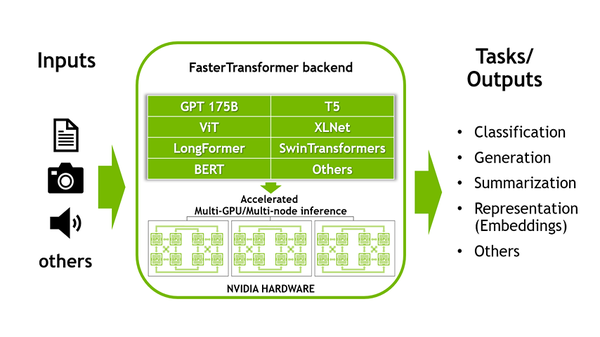
The post includes several code examples to illustrate how you can activate high-performance batching, preprocessing, and multi-node inference; and implement online learning.
LinkedIn Link
Twitter Link
Facebook Link
Email Link
Recommended For You
webpage:
Session
Optimizing Inference and New LLM Features in Desktops and Workstations
webpage:
Session
An AI Revolution in Insurance Claim Process
webpage:
Session
Benchmarking LLMs With Triton Inference Server
webpage:
Session
Accelerate LLM Inference With TensorRT-LLM
webpage:
Session
Fast and Memory-Efficient Exact Attention With IO-Awareness
webpage:
Session
Accelerating Generative AI With TensorRT-LLM to Enhance Seller Experience at Amazon
webpage:
Session
Optimizing Your LLM Pipeline for End-to-End Efficiency
webpage:
Blog
How to Deploy an AI Model with PyTriton
webpage:
Blog
Deploying a 1.3B GPT-3 Model with NVIDIA NeMo Framework
webpage:
Blog
Accelerated Inference for Large Transformer Models Using NVIDIA Triton Inference Server
webpage:
Blog
Deploying GPT-J and T5 with NVIDIA Triton Inference Server
webpage:
Webinar
Harness the Power of Cloud-Ready AI Inference Solutions and Experience a Step-By-Step Demo of LLM Inference Deployment in the Cloud
NVIDIA websites use cookies to deliver and improve the website experience. See our
cookie policy
for further details on how we use cookies and how to change your cookie settings.
Accept