NEXT

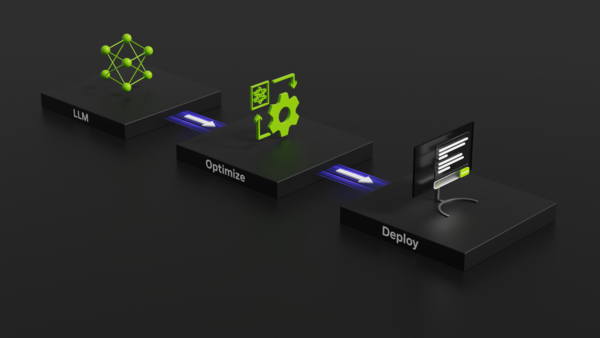
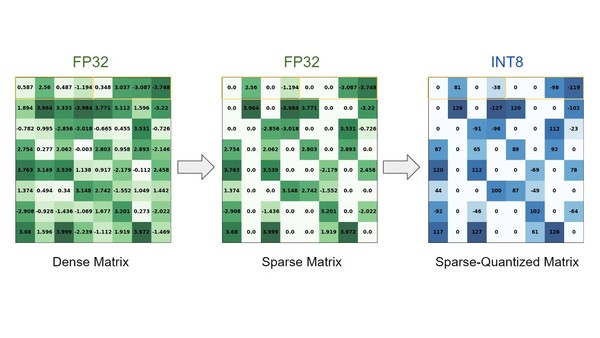
Leveraging Quantization in TensorRT-LLM and TensorRT
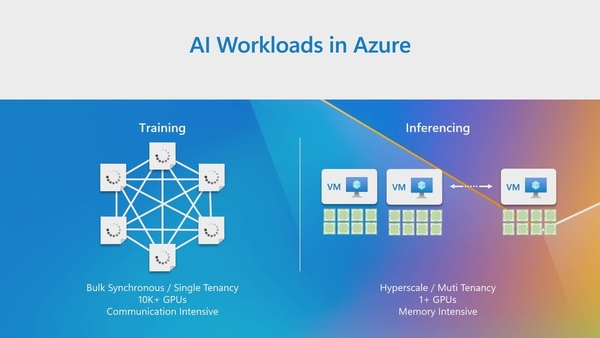
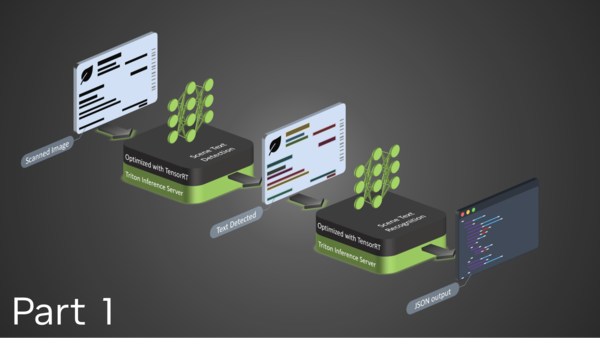
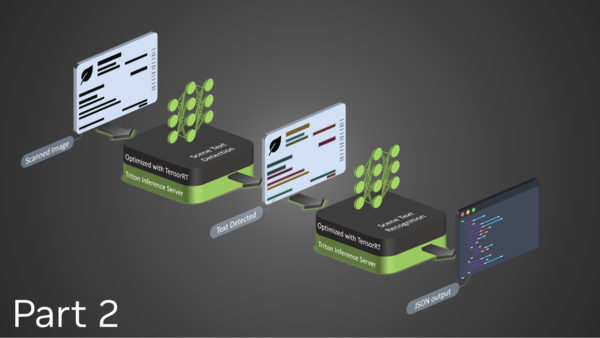
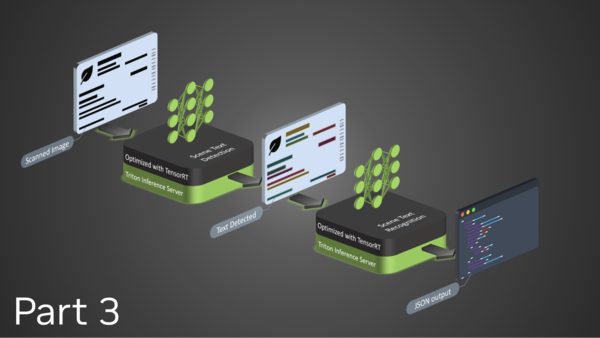
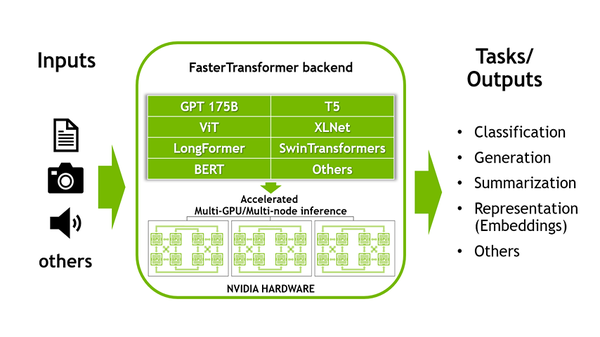
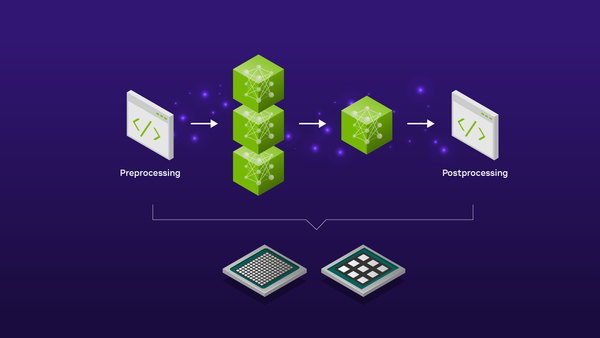
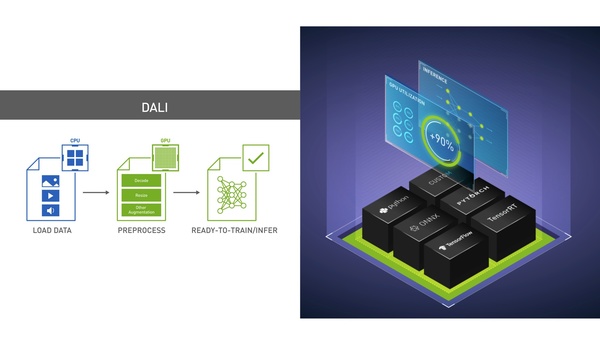
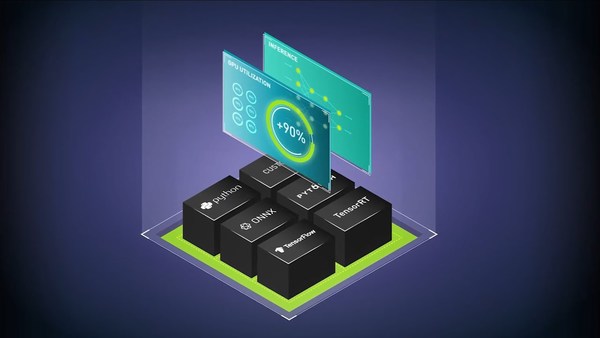
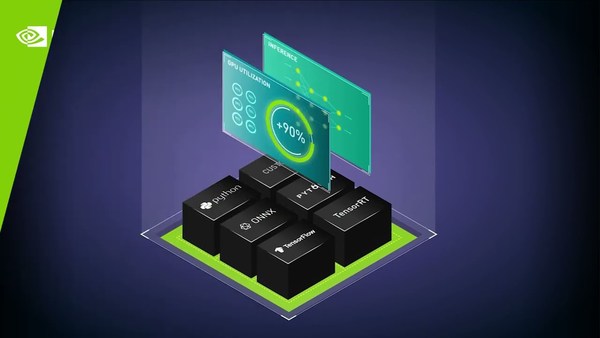
This tutorial session highlights an end-to-end optimization-to-deployment demo for language models with TensorRT-LLM and Stable Diffusion models with TensorRT.

Get in Touch
Learn more about purchasing our AI inference software for production deployment.Recommended For You



































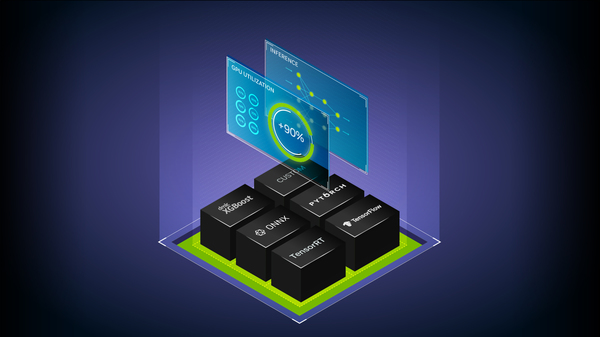
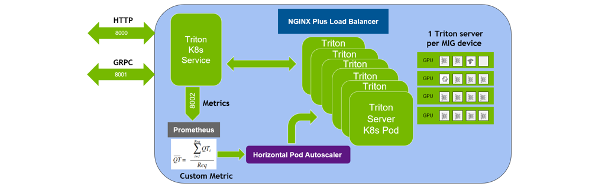
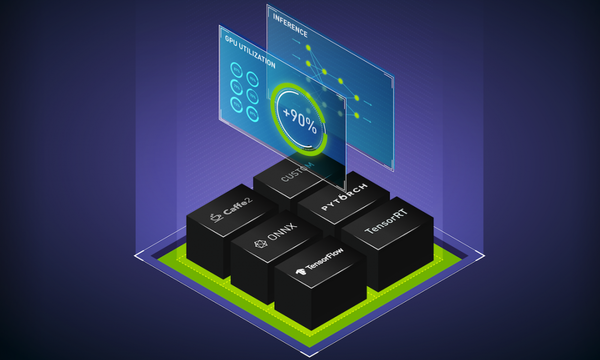


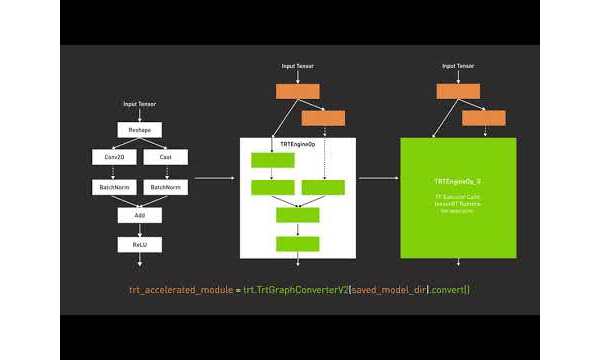
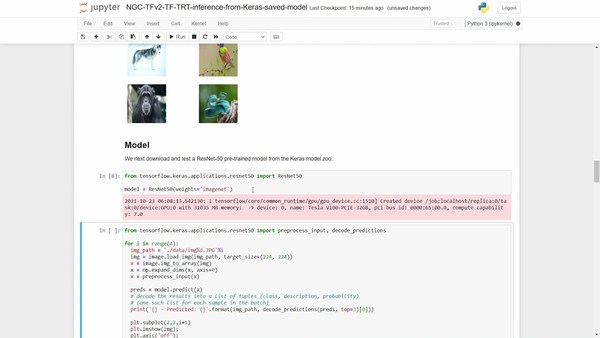
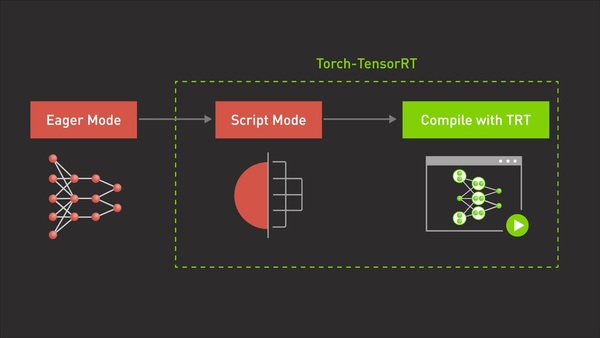





Fill This Out to Continue
This content will be available after you complete this form.